Redis
一、缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
有些人可能在短时间内恶意发送大量这样的请求,导致数据库崩溃。
常见解决方案:
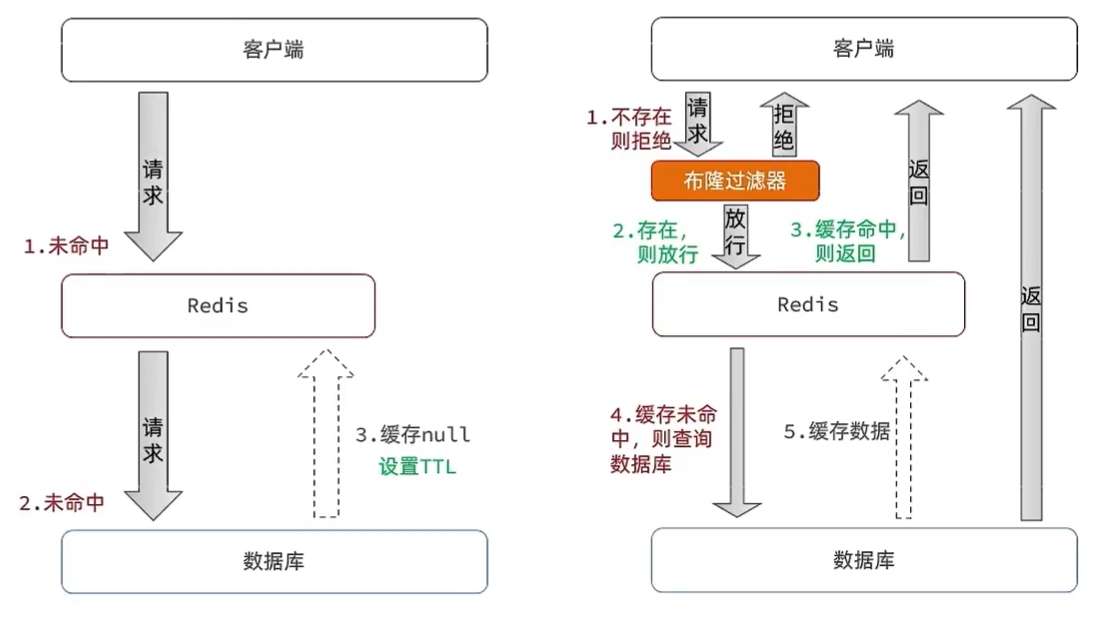
1、缓存空对象
优点:实现简单,维护方便
缺点:1、额外的内存消耗 2、可能造成短期的不一致
2、布隆过滤
优点:内存占用较少,没有多余key
缺点:1、实现复杂 2、存在误判可能(查不到->数据库是真的没有,查到了->不一定真的有)
3、主动防范
增强id的复杂度,避免被猜测id规律
做好数据的基础格式校验
加强用户权限校验
热点参数限流
二、缓存雪崩(面、所有点)
同一时段大量的缓存key同时失效或者Redis服务宕机(缓存的所有key失效),导致大量请求到达数据库,带来巨大压力。
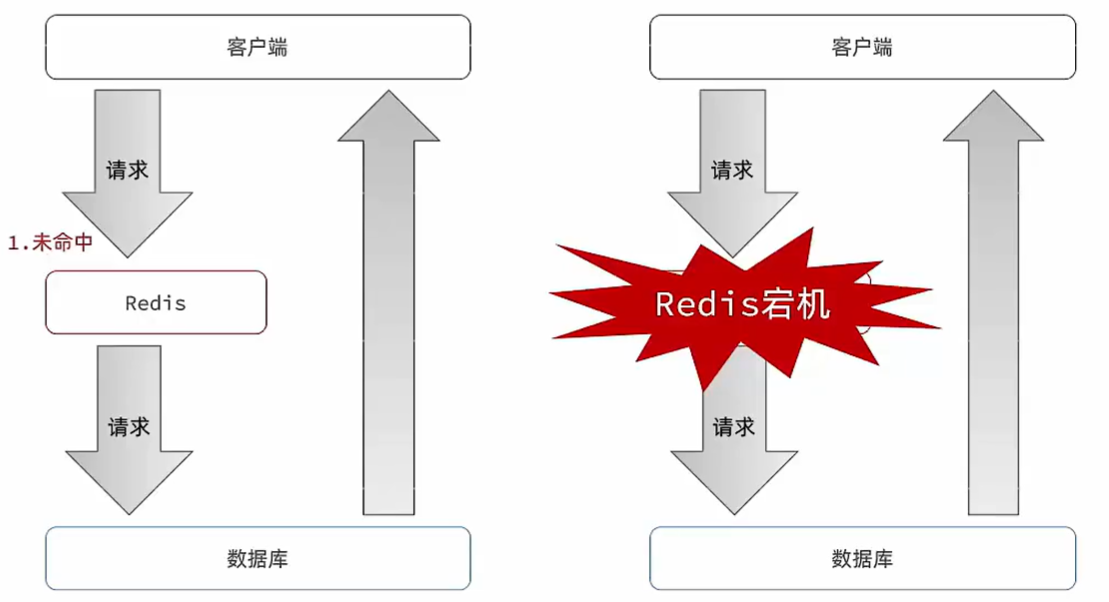
解决方案:
- 给不同的key的TTL添加随机值
- 利用Redis集群(主-从,一个坏了另一个顶上来)提高服务的可用性
- 给缓存业务添加降级限流策略(快速失败,拒绝服务)
- 给业务添加多级缓存
三、缓存击穿(点)
也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
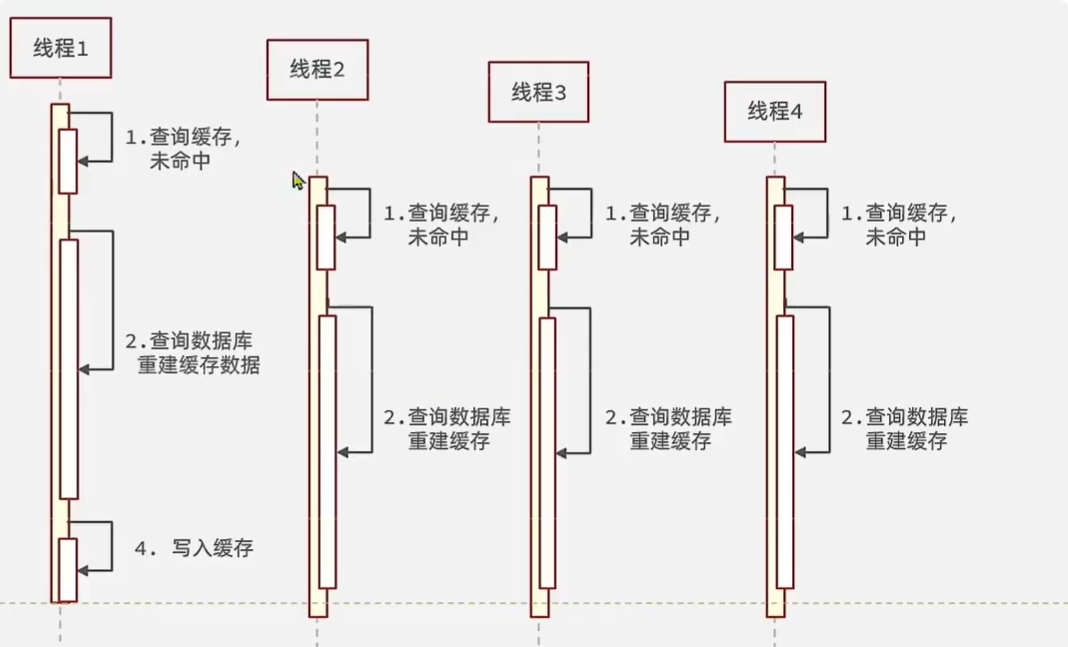
解决方案:
- 互斥锁
- 逻辑过期
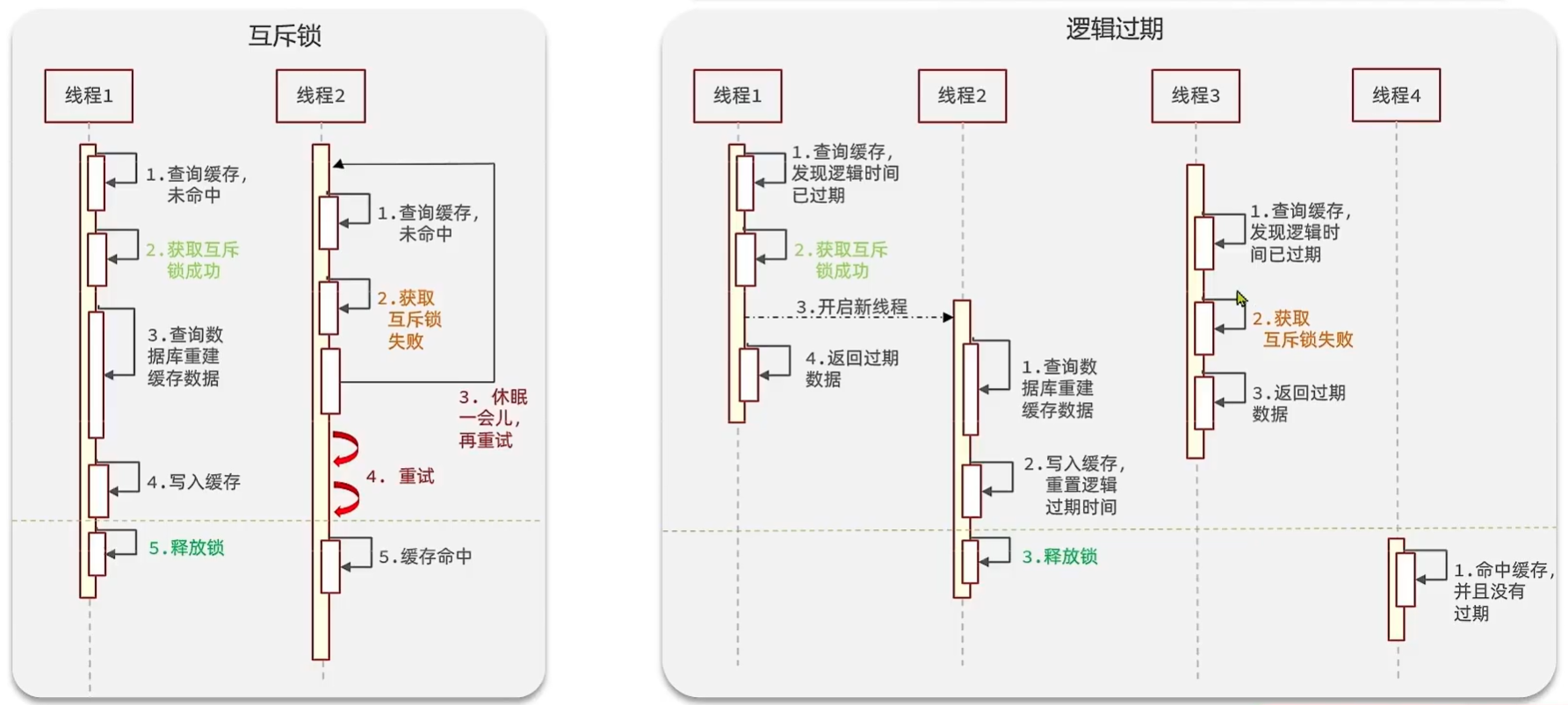
互斥锁
这里的互斥锁,如果一个线程发现锁被占用了,需要休眠一会再重试,官方实现的锁如果拿不到都会阻塞,不能实现我们想要的功能,所以这里需要自己设计锁(通过redis)。
使用setnx功能
1 | setnx lock 1 // 添加锁,后续别的线程无法再修改这个锁 |

逻辑过期
由于缓存击穿是针对高并发访问的数据的,所以逻辑过期方案选择提前主动把相关数据放到redis,防止大量请求到达数据库。如果在redis中查询不到这些内容时,就直接返回null,不再去数据库查询了。
四、Redis持久化
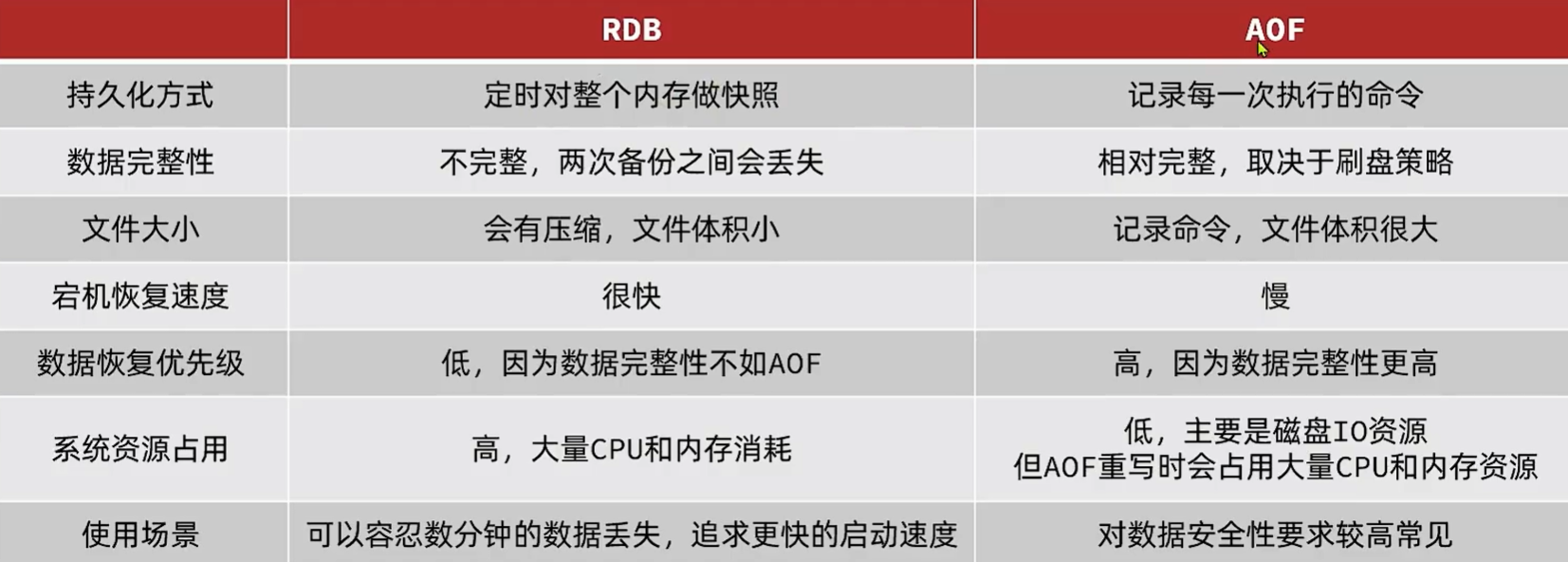
RDB
Redis Database Backup file(Redis数据备份文件),也叫做Redis数据快照。把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。默认是保存在当前运行目录。
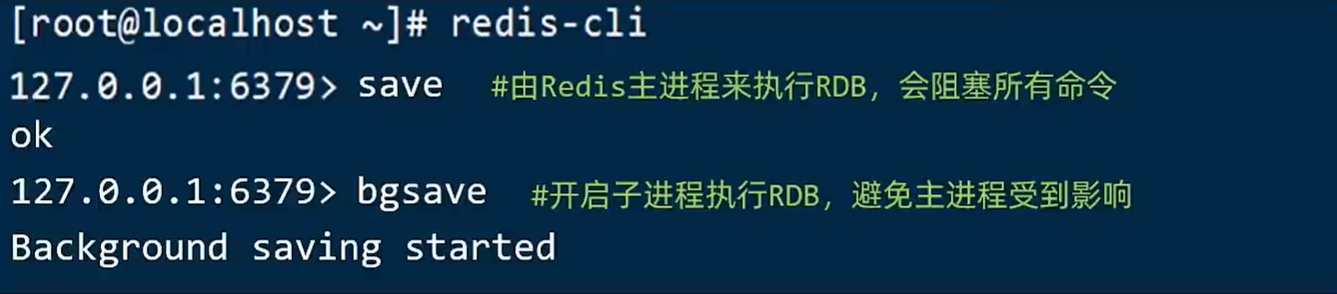
停机会自动执行一次RDB。
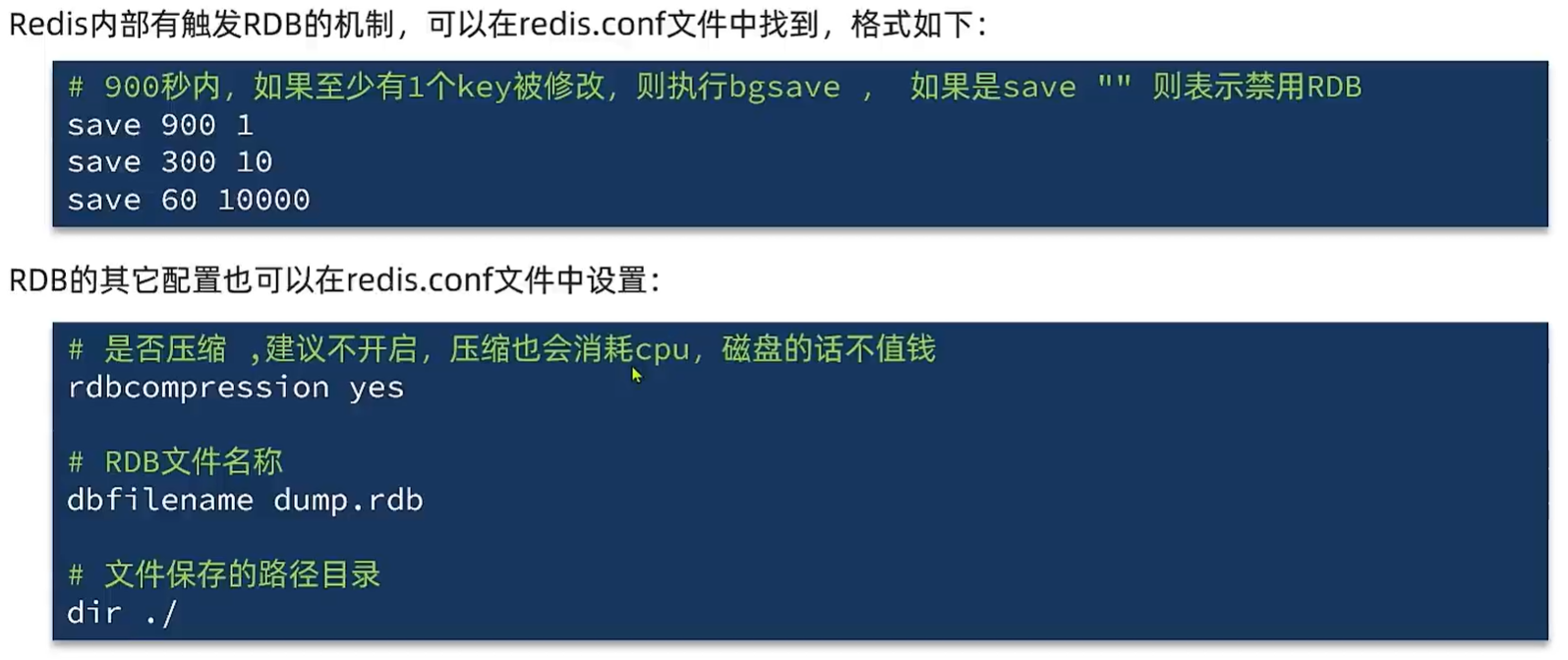
配置
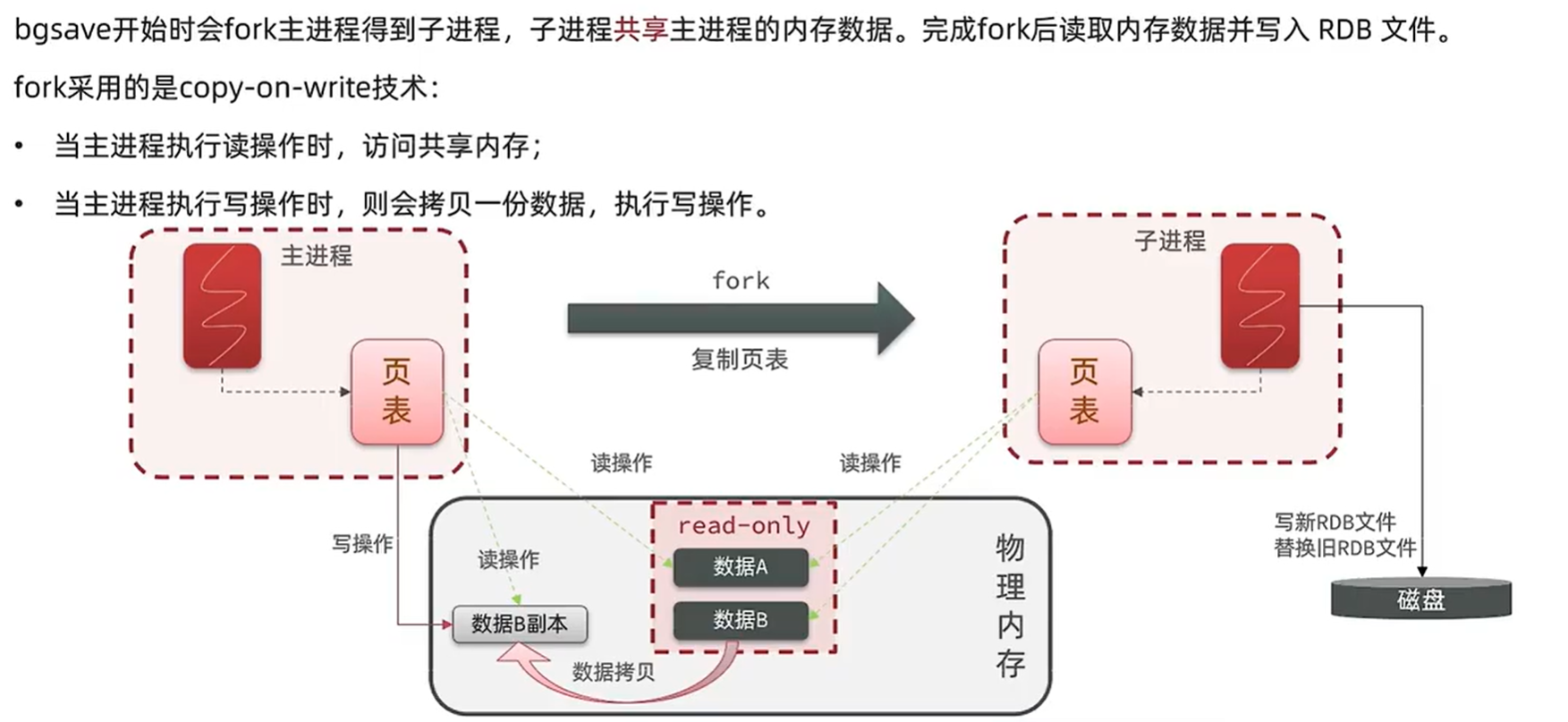
bgsave底层原理
AOF
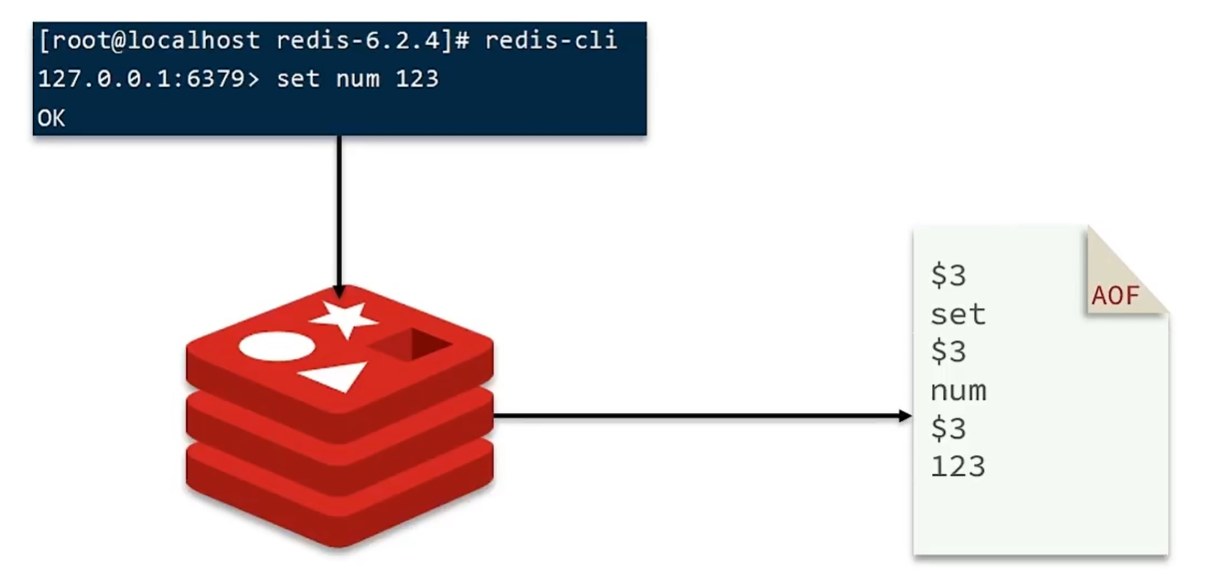
Append Only File(追加文件)。Redis处理的每一个写命令都记录在AOF文件中,可以看作是命令日志文件。
默认不开启,需要在redis.config中禁用RDB,并开启AOF。
save ""禁用RDB
appendonly yes开启AOF
配置

因为是记录命令,AOF文件会比RDB文件大很多。并且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。
通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

配置自动重写:

总结
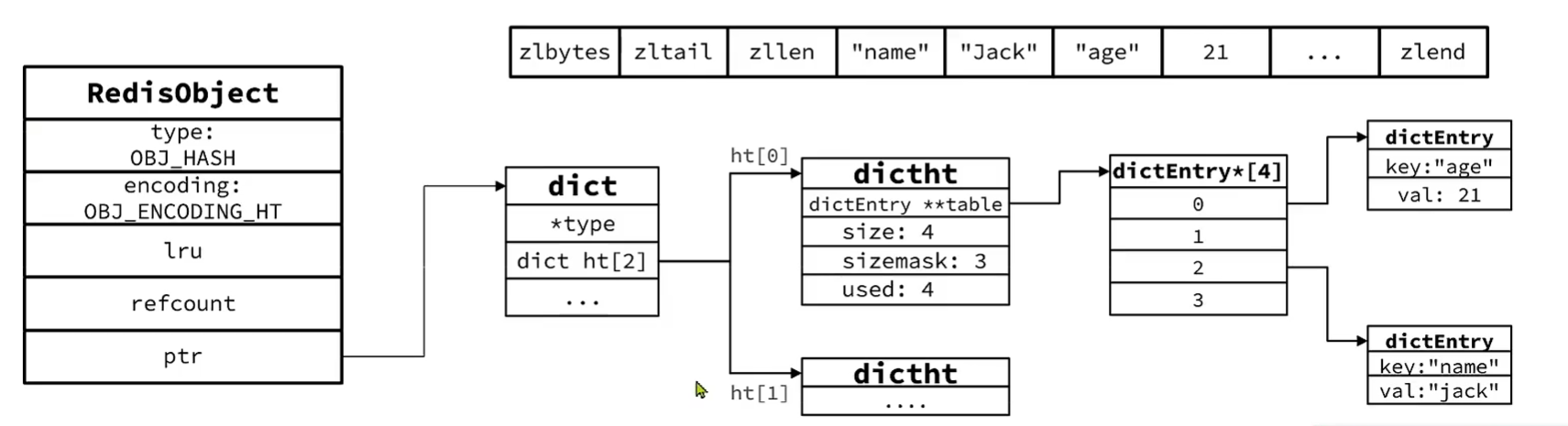
五、数据结构
1、String
最常见的数据存储类型。
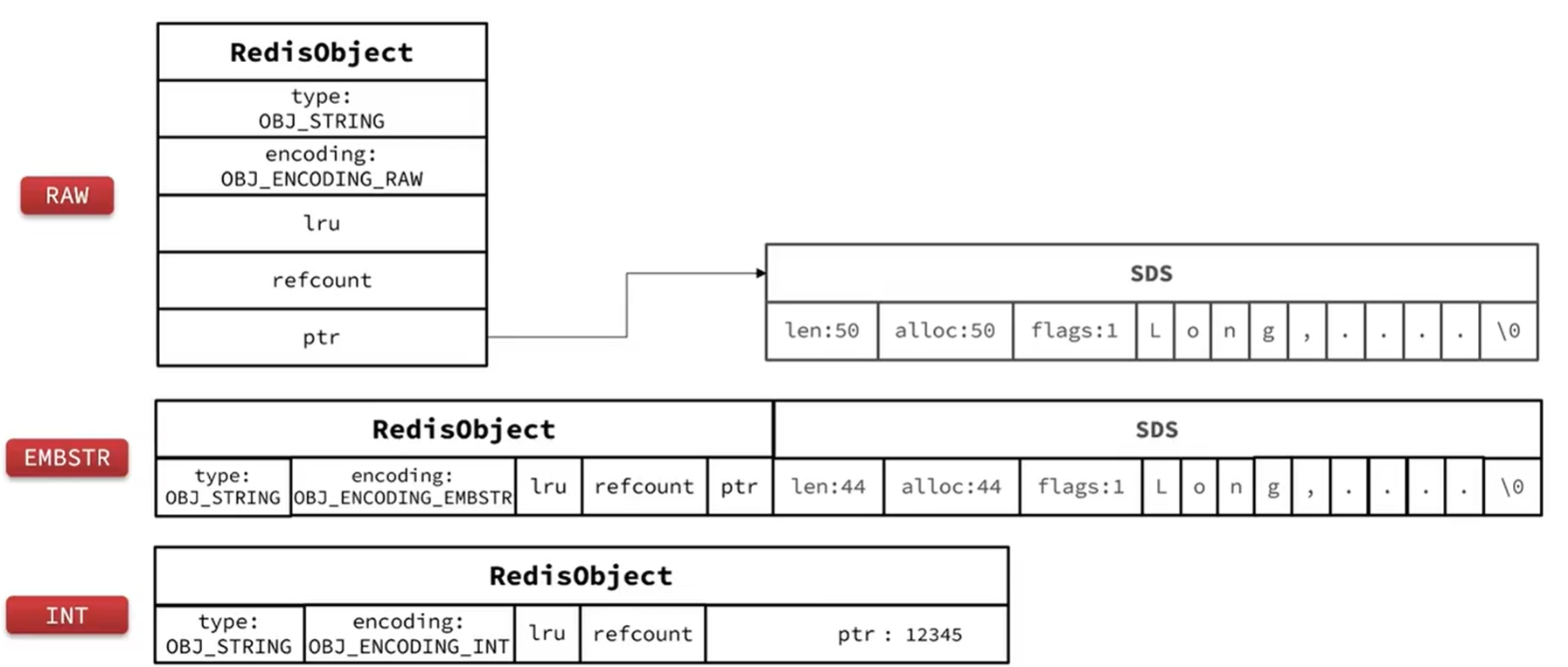
- 基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
- 如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续的空间。申请内存时只需要调用一次内存分配函数,效率更高。(为什么是44字节?因为字符串为44字节时,SDS和redisobject的总长度为64字节,是2^n的,在分配内存的时候不会产生内存碎片。)
- 如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS。
SDS结构:

2、List

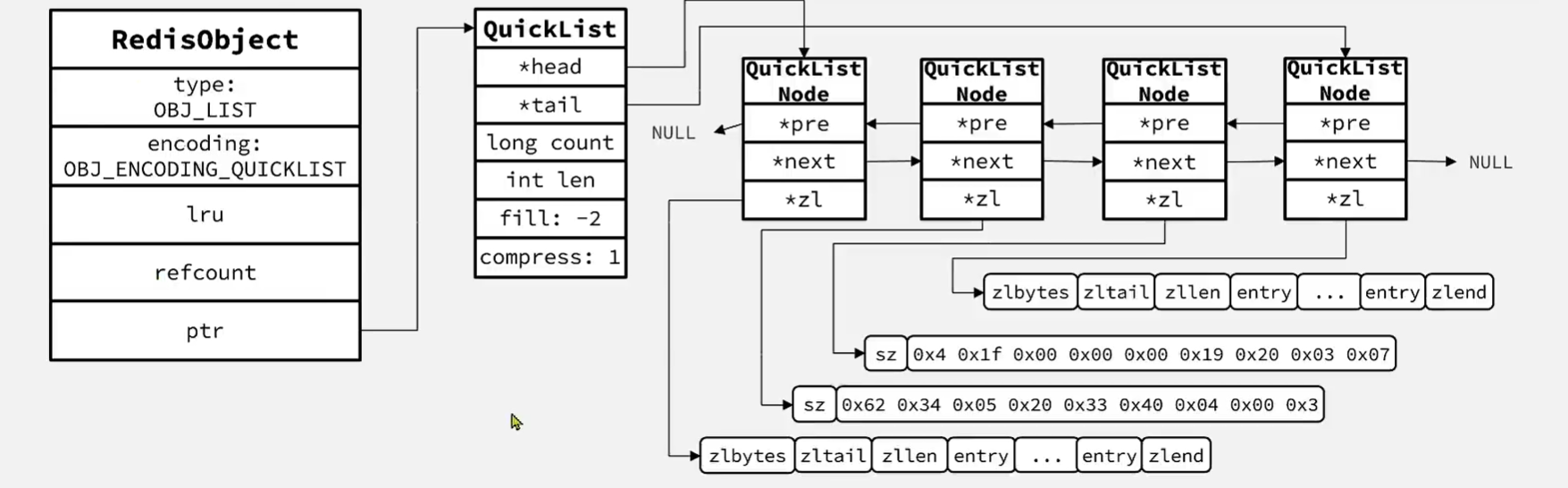
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素:
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,Redis统一采用QuickList来实现List。
3、Set
Redis的单列集合,满足下列特点:
- 不保证有序性
- 元素唯一(可以判断元素是否存在)
- 求交并差集
存储流程
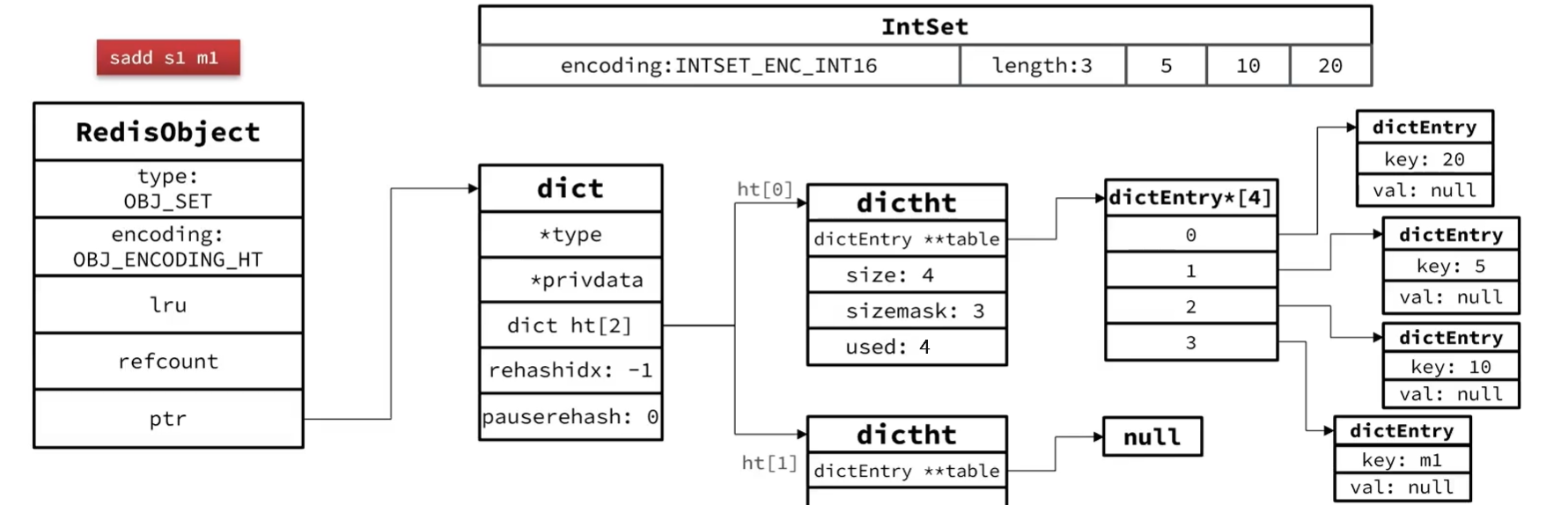
使用HashTable编码(Dict)。Dict中的key用来存储元素,value统一为null。
当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存。
4、ZSet
也就是SortedSet,其中每一个元素都需要指定一个score值和member值:
- 可以根据score值排序(值越小排在越前面)
- member必须唯一
- 可以根据member查询分数
实现方式一:
SkipList:可以排序,并且可以同时存储score和ele值(member)
HT(Dict):可以键值存储,并且可以根据有key找value
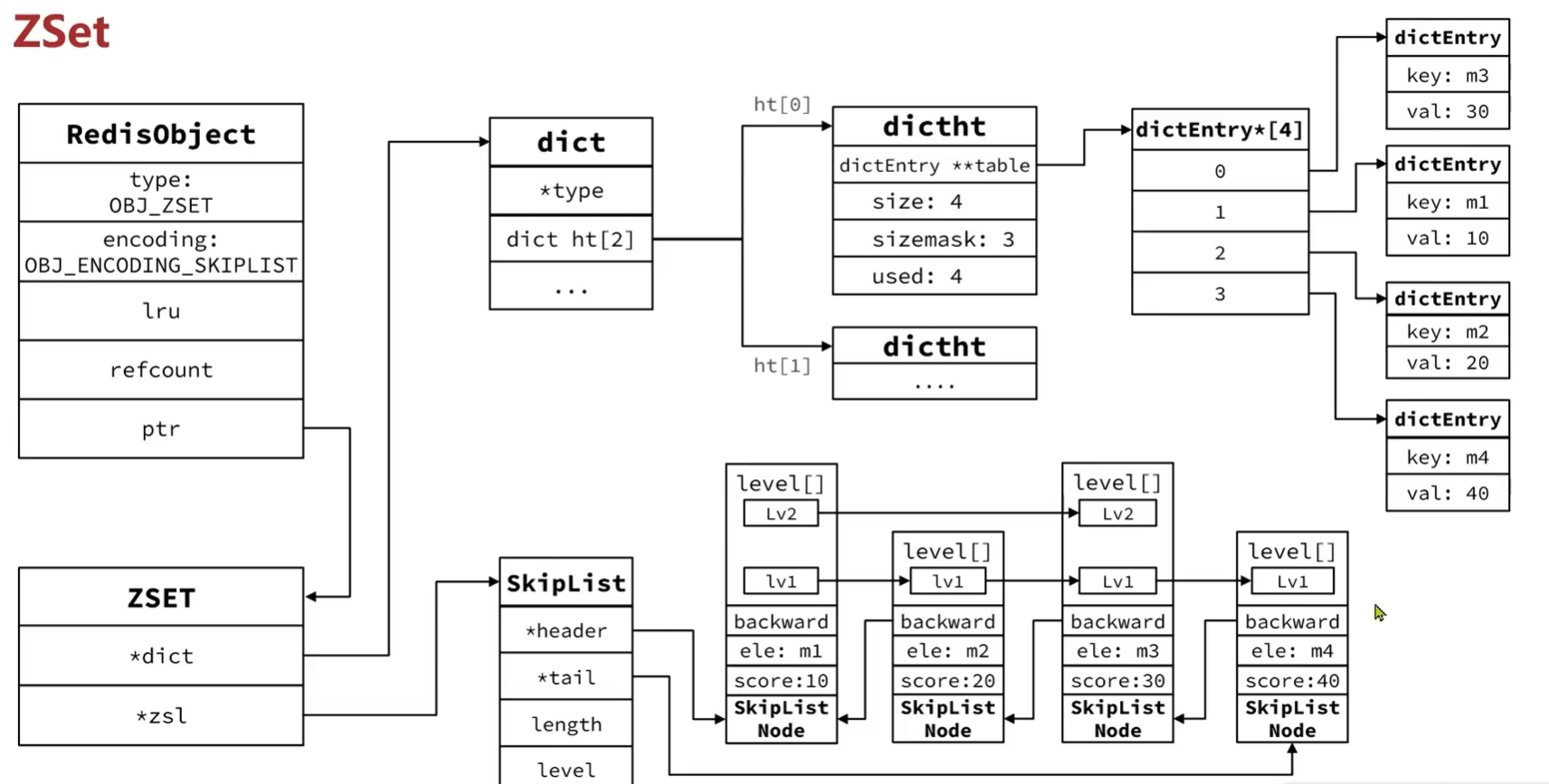
SkipList工作原理:
查找:总是从最高层的最左侧开始
- 观察当前层右侧的下一个节点的值
- 如果右侧节点的值 小于 目标值,说明还没到,继续 向右 走。
- 如果右侧节点的值 大于 目标值,或者右侧是空(链表尾部),说明目标值必然在这两个节点之间,于是向下降一层,重复步骤 1 和 2。
- 知道降到第0层并找到目标,或者确认目标不存在
(这个过程很像先坐只停大站的快车逼近目的地,再换慢车精准到达)
插入:
先走一遍查找流程,找到新元素在第0层的插入位置,并把它插进去
随机函数确定是否要把新节点提拔一层(在第一层也建立这个节点并链接)
继续随机函数,判断是否要提拔到第2层,直到不提拔为止
实现方式二:
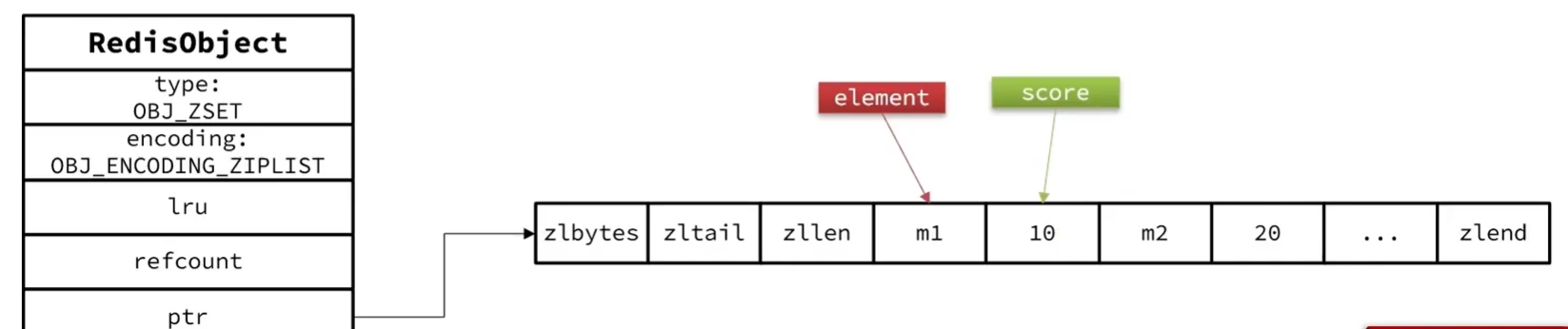
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset会使用ZipList结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于zset_max_ziplist_entries,默认值128
- 每个元素都小于zset_max_ziplist_value字节,默认64
Ziplist本身没有排序功能,且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element可以紧挨在一起,存在两个entry中,element在前,score在后
- score越小越接近队首,按照score值升序排列
5、Hash
与Zset非常类似:
- 都是键值存储
- 都需要根据键获取值
- 键必须唯一
区别:
- zset的键是member,值是score;hash的键和值都是任意值
- zset要根据score排序;hash无需排序
因此,hash底层采用的编码与Zset也基本一致,只需要把排序有关的SkipList去掉。
Hash结构默认采用ZipList编码,以节省内存。相邻两个entry分别保存field和value
当数量较大时,Hash结构会转为HT编码,触发条件有两个:
- ZipList中的元素数量超过hash_max_ziplist_entries,默认512
- 任意entry大小超过hash_max_ziplist_value字节,默认64