JUC
一、Java线程
1.1 创建和运行线程
方法一、直接使用Thread
1 | // 创建线程对象 |
方法二、使用Runnable配合Thread
把线程和任务(要执行的代码)分开
- Thread代表线程
- Runnabnle代表可运行的任务(线程要执行的代码)
1 | // 创建任务对象 |
lambda表达式:
(鼠标放在类上,按alt + enter IDE可以自动将其转换成lambda表达式)
1 | // 创建任务对象 |
甚至可以更简洁:
(一行代码直接创建线程对象和任务对象)
1 | Thread t2 = new Thread(() -> {log.debug("hello");}, "t2"); |
原理
最终走的都是thread的run方法,只是run方法的实现不同,第一种是自己的匿名内部类来实现的,第二种是通过Runnable里面的run方法来执行的
小结:
- 方法1 是把线程和任务合并在了一起,方法2 是把线程和任务分开了
- 用 Runnable 更容易与线程池等高级 API 配合
- 用 Runnable 让任务类脱离了 Thread 继承体系,更灵活
方法三、FutureTask配合Thread
FutureTask 能够接收 Callable 类型的参数,用来处理有返回结果的情况
FutureTask间接实现了Runnable接口,所以也可以作为任务对象。
1 | // 创建任务对象 |
二、线程状态
2.1《操作系统》层面
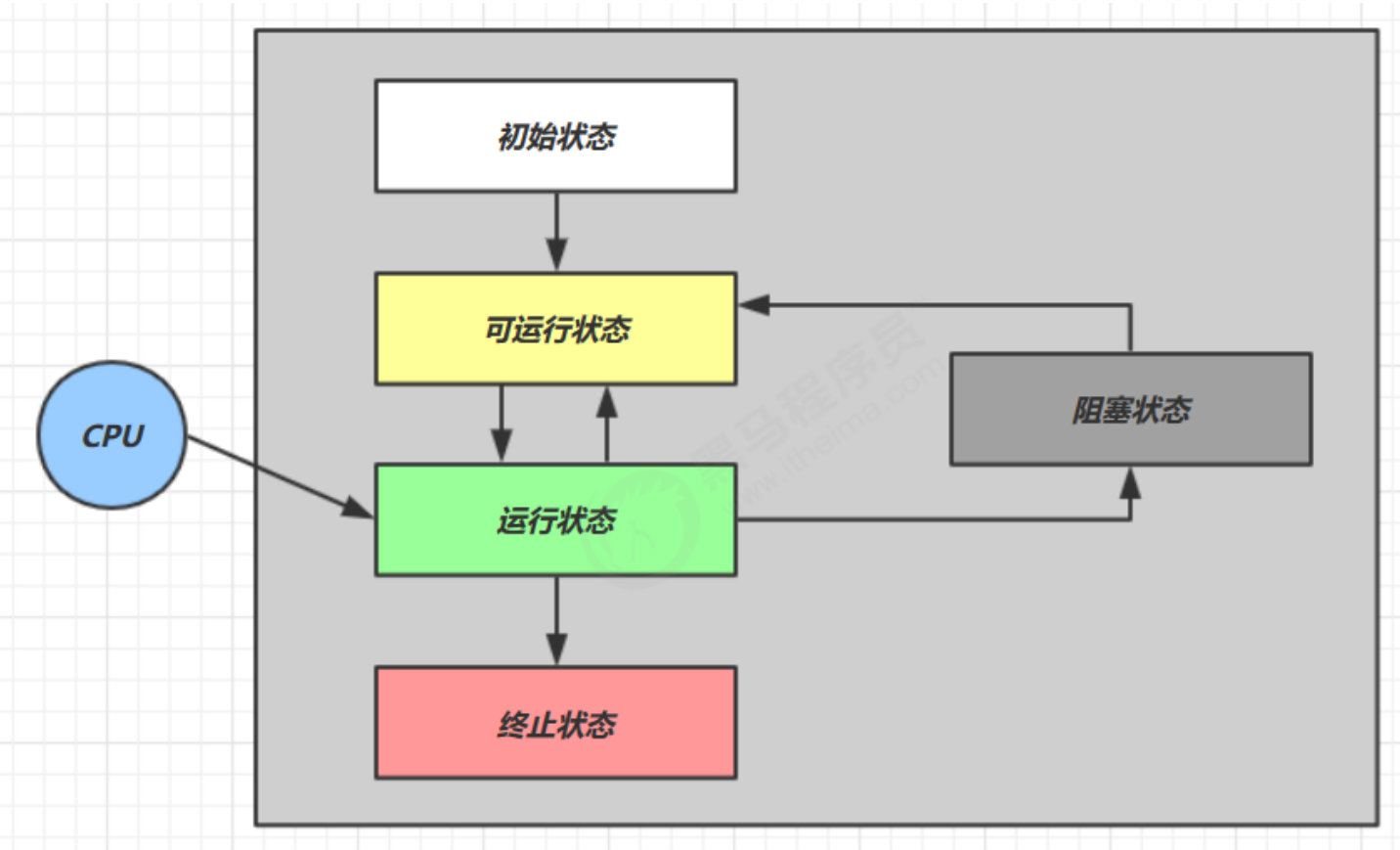
- 【初始状态】:仅在语言层面创建了线程对象,还未与操作系统线程关联
- 【就绪状态】:除了CPU,其他资源都已经分配完毕
- 【运行状态】:获得了CPU时间片,正在运行
- 【阻塞状态】:IO等情况,线程上下文切换,该线程进入阻塞状态
- 【终止状态】:线程已经执行完毕
2.2 JAVA层面
JAVA认为只要不是人为主动阻塞的就一直是RUNNABLE状态
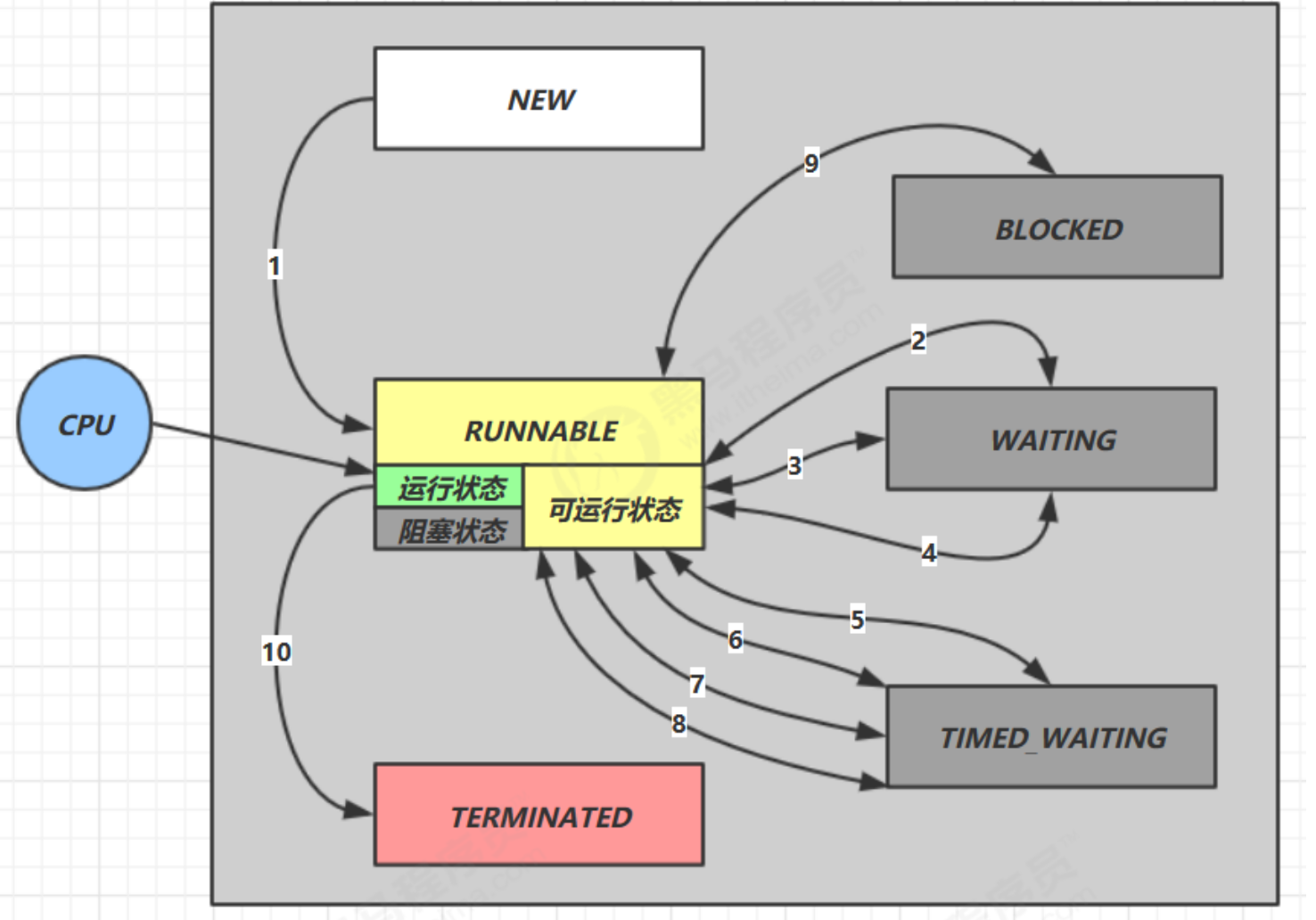
timed_waiting:明确规定时间的等待
waiting:没有时间的等待
blocked:拿不到锁进入blocked状态
三、synchronized优化
3.1 轻量级锁
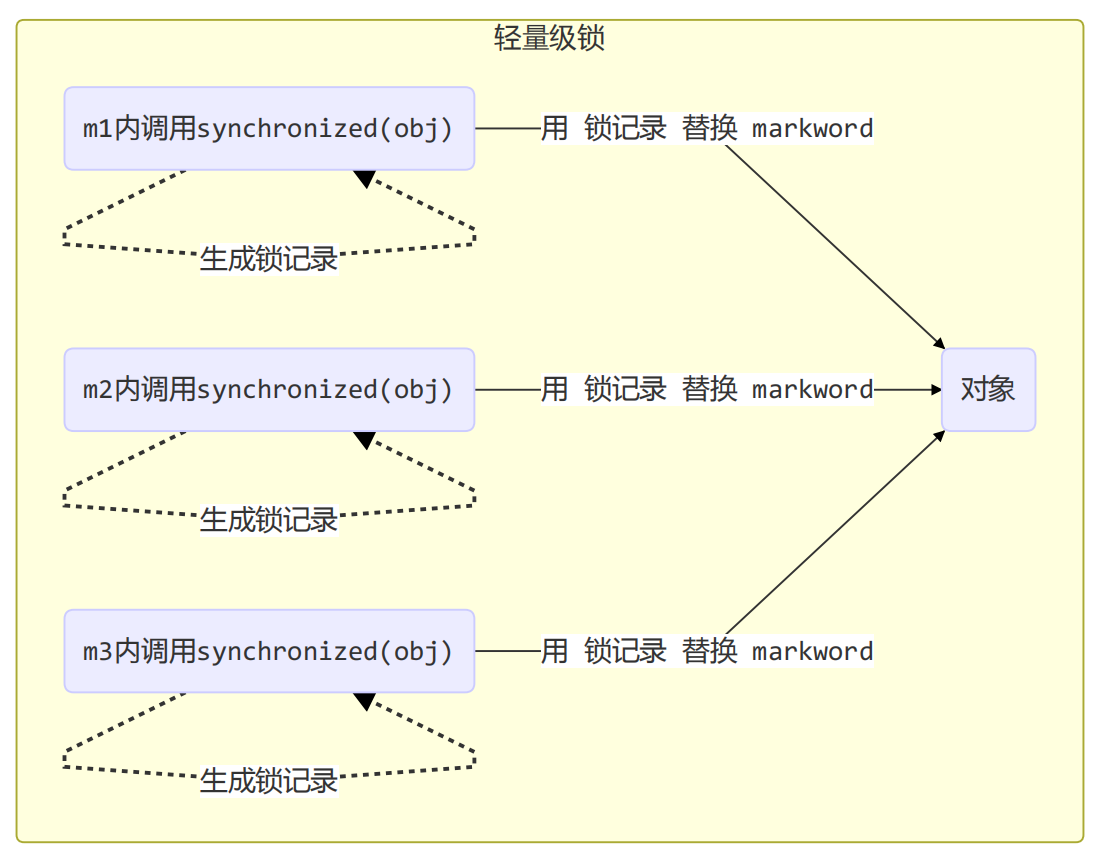
使用场景:如果一个对象虽然有多线程访问,但多线程访问的时间是错开的(没有竞争),那么可以使用轻量级锁来优化。
轻量级锁对使用者是透明的,即语法仍然是synchronized

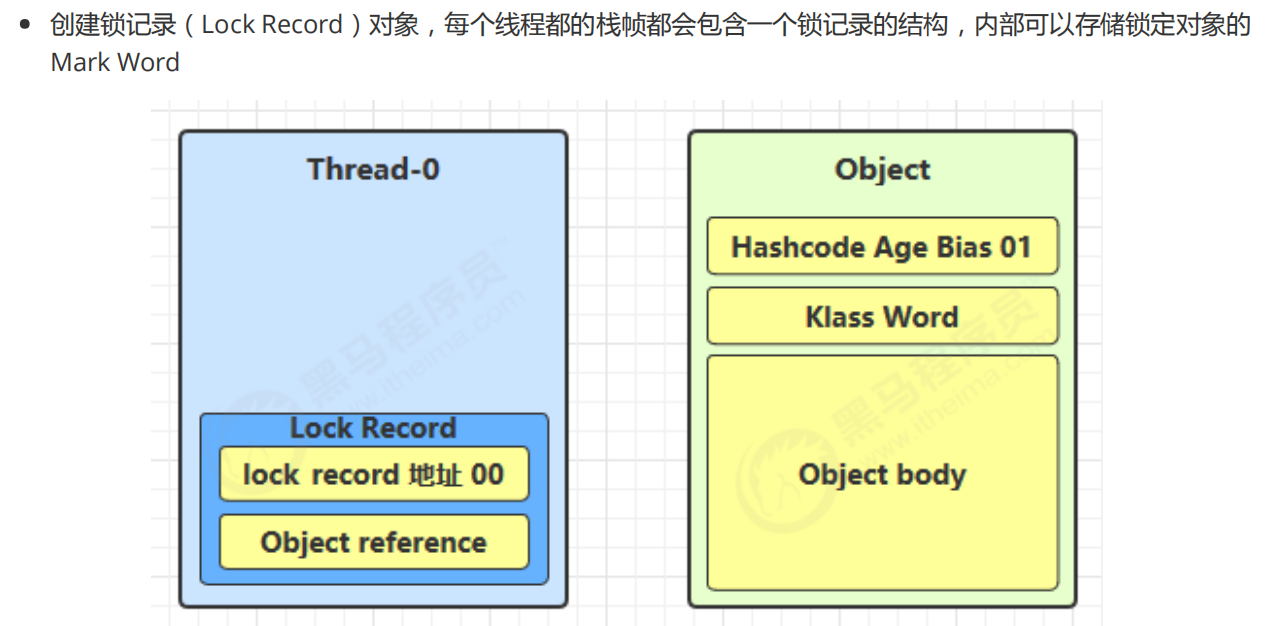
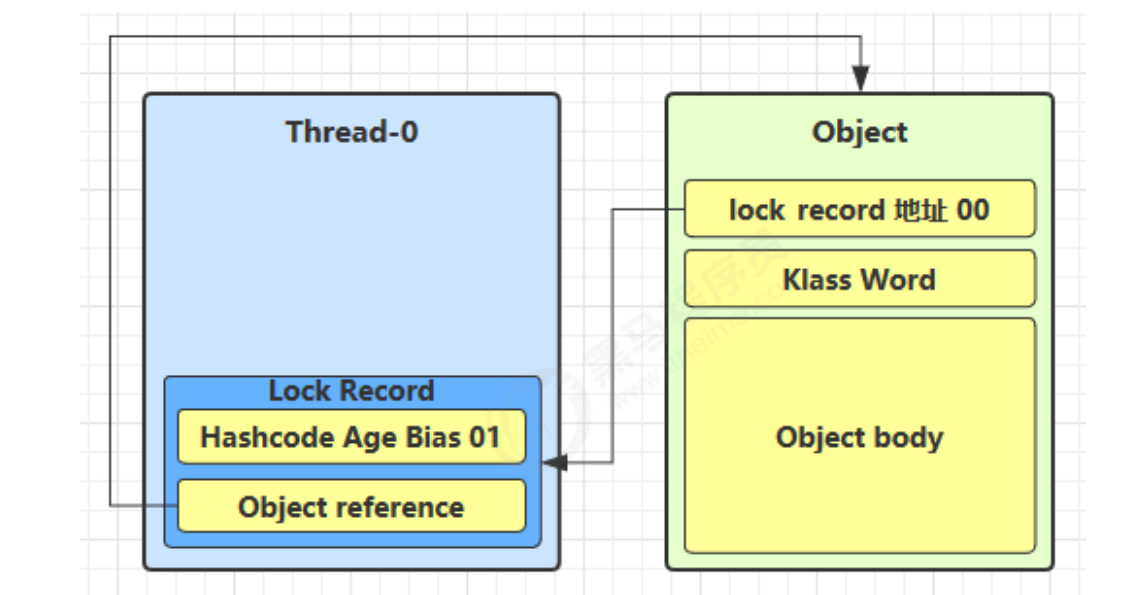
- 让锁记录中 Object reference 指向锁对象,并尝试用 cas 替换 Object 的 Mark Word,将 Mark Word 的值存入锁记录
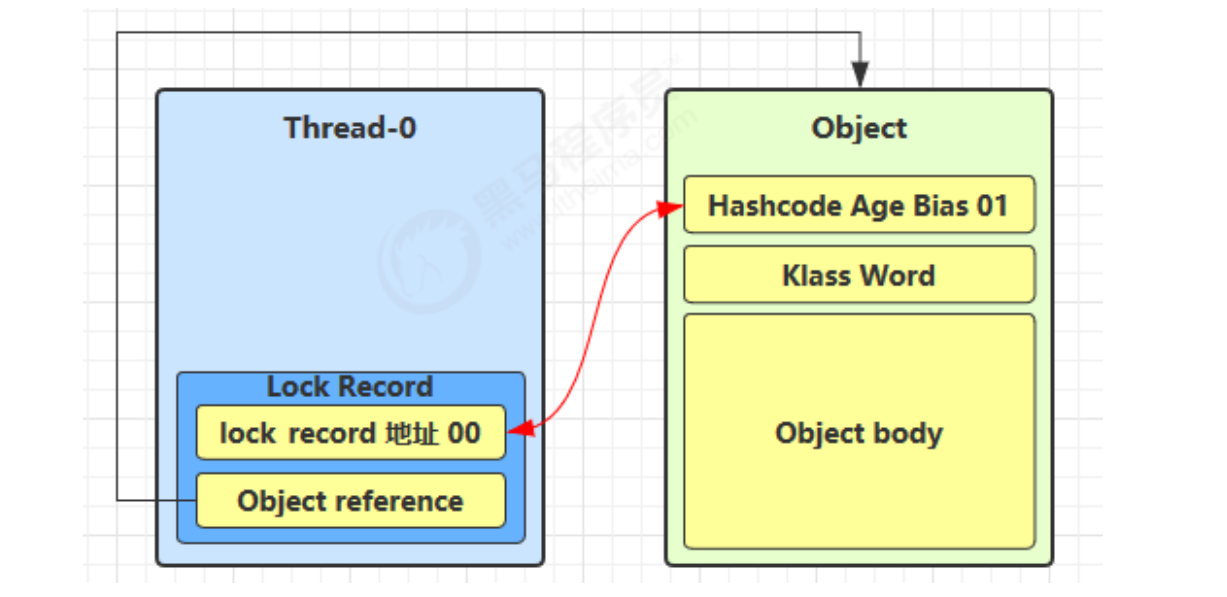
- 如果 cas 替换成功,对象头中存储了
锁记录地址和状态 00,表示由该线程给对象加锁,这时图示如下
如果 cas 失败,有两种情况
如果是其它线程已经持有了该 Object 的轻量级锁,这时表明有竞争,进入锁膨胀过程
如果是自己执行了 synchronized 锁重入,那么再添加一条 Lock Record 作为重入的计数
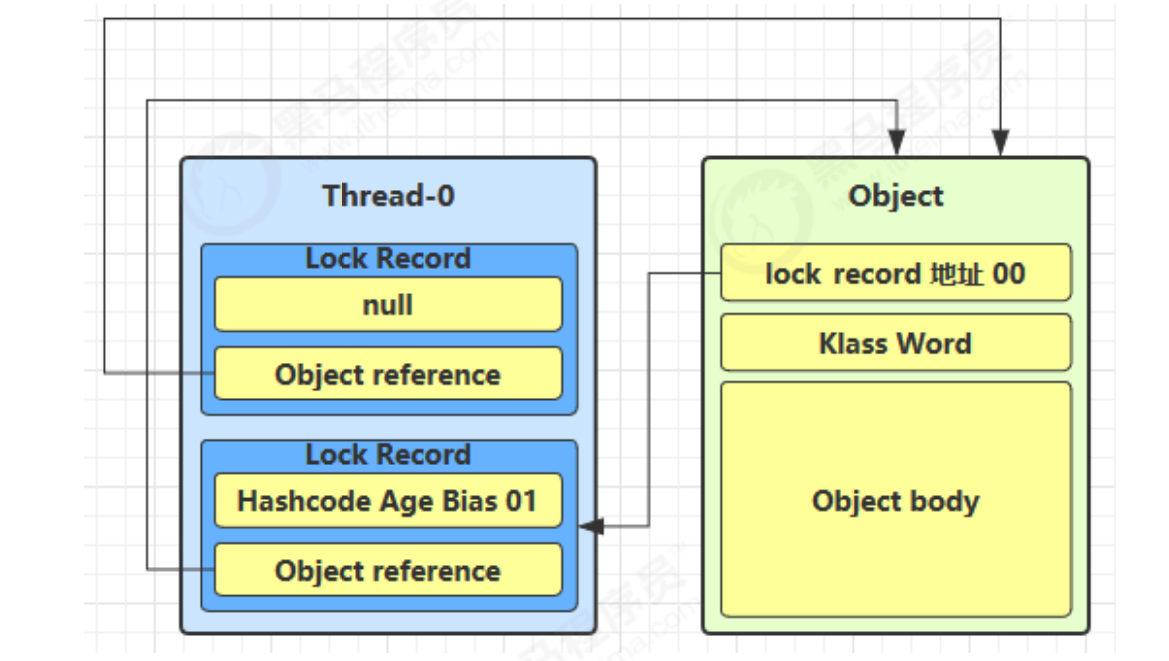
- 当退出 synchronized 代码块(解锁时)如果有取值为 null 的锁记录,表示有重入,这时重置锁记录,表示重入计数减一
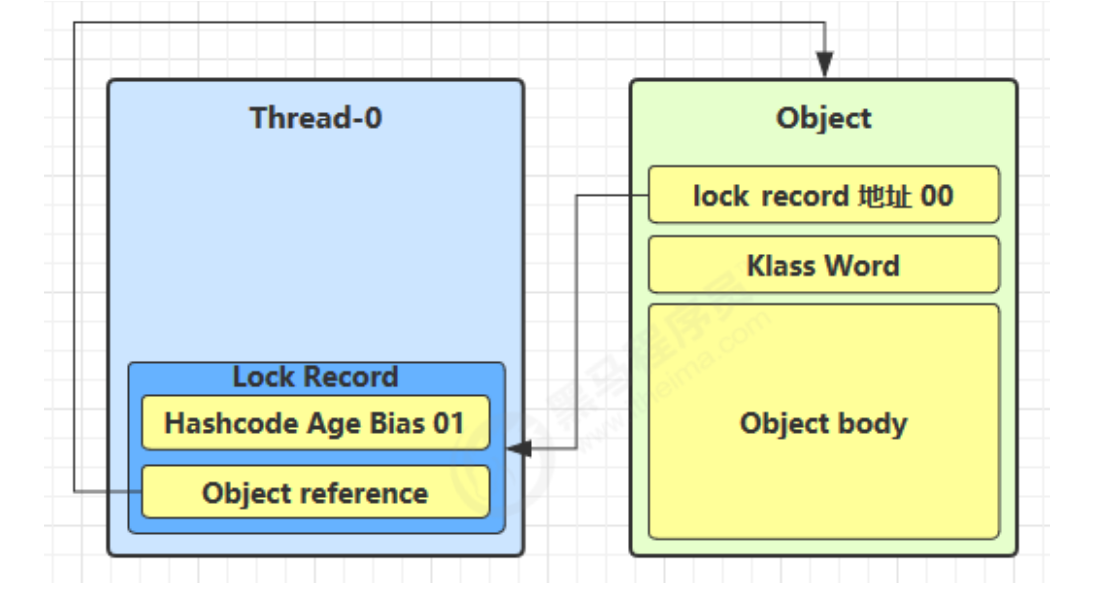
- 当退出 synchronized 代码块(解锁时)锁记录的值不为 null,这时使用 cas 将 Mark Word 的值恢复给对象头
- 成功,则解锁成功
- 失败,说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程
3.2 锁膨胀
如果在尝试加轻量级锁的过程中,CAS 操作无法成功,这时一种情况就是有其它线程为此对象加上了轻量级锁(有竞争),这时需要进行锁膨胀,将轻量级锁变为重量级锁。
- 当 Thread-1 进行轻量级加锁时,Thread-0 已经对该对象加了轻量级锁
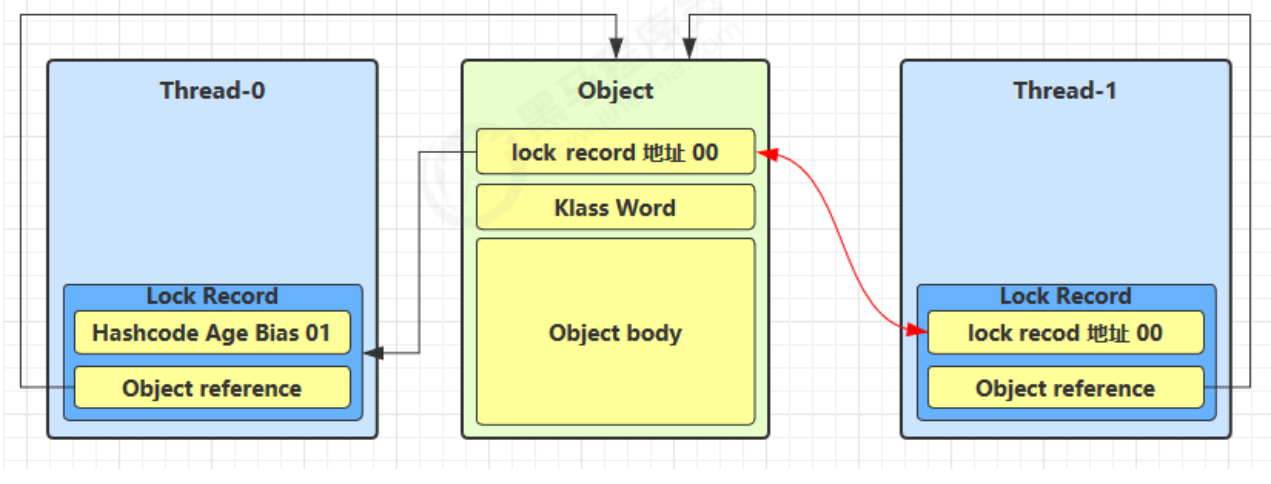
这时 Thread-1 加轻量级锁失败,进入锁膨胀流程
即为 Object 对象申请 Monitor 锁,让 Object 指向重量级锁地址
然后自己进入 Monitor 的 EntryList BLOCKED
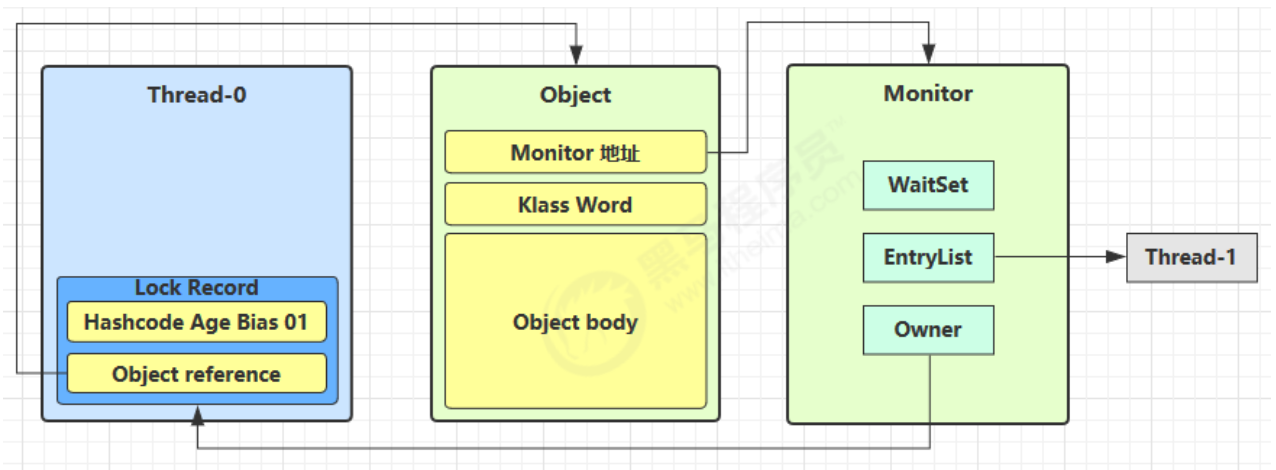
- 当 Thread-0 退出同步块解锁时,使用 cas 将 Mark Word 的值恢复给对象头,失败。这时会进入重量级解锁流程,即按照 Monitor 地址找到 Monitor 对象,设置 Owner 为 null,唤醒 EntryList 中 BLOCKED 线程
3.3 自旋优化
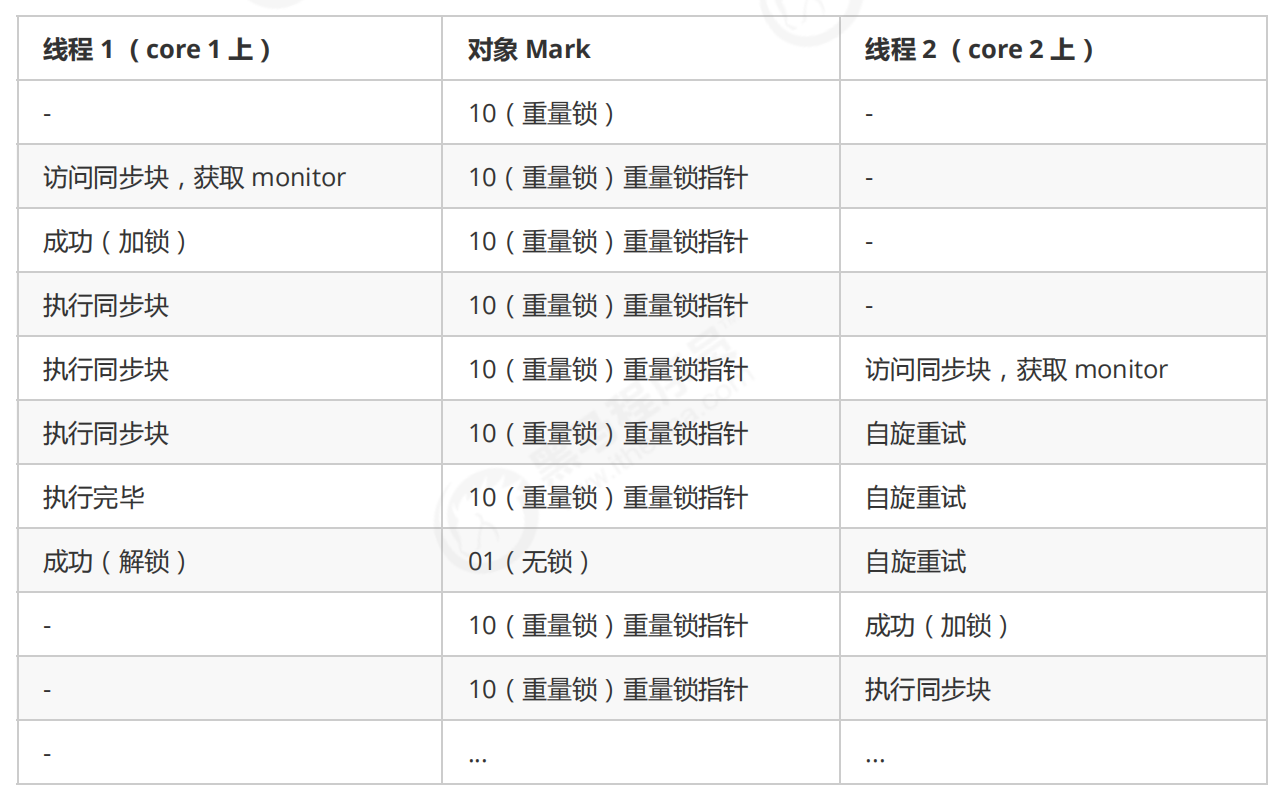
重量级锁竞争的时候,还可以使用自旋来进行优化,如果当前线程自旋成功(即这时候持锁线程已经退出了同步块,释放了锁),这时当前线程就可以避免阻塞。
自旋重试成功的情况:
自旋重试失败的情况:
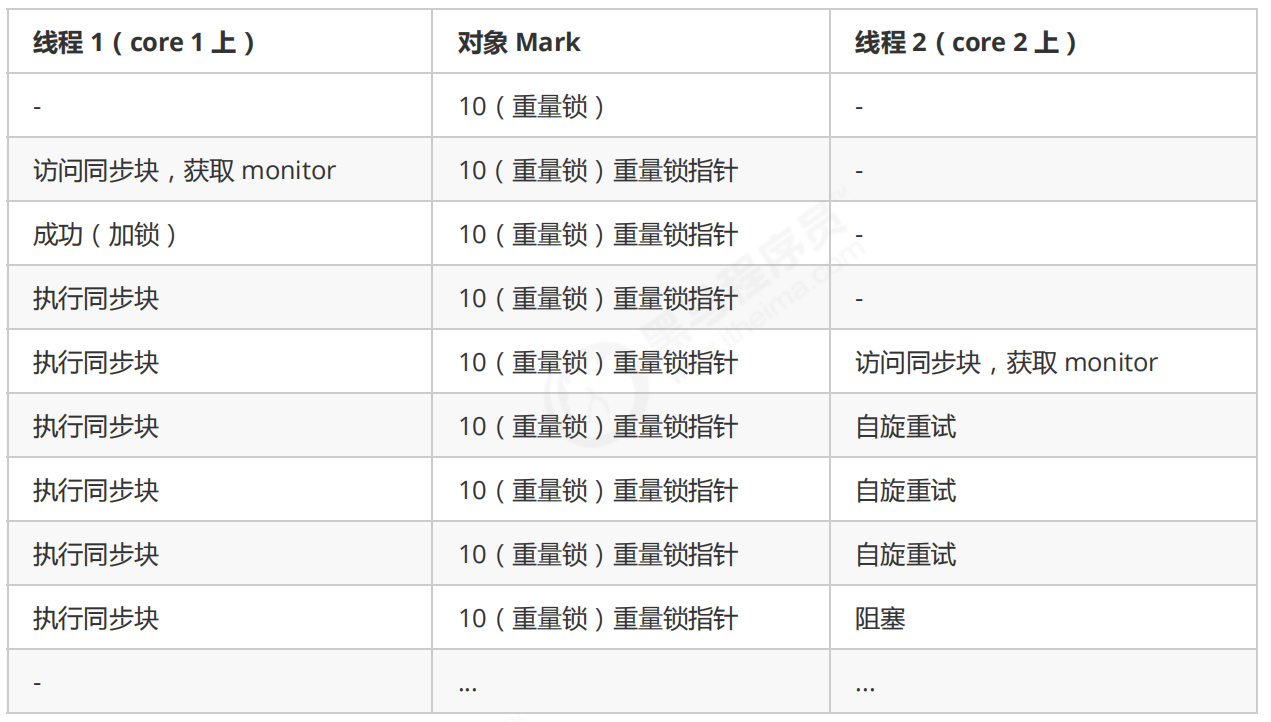
自旋会占用 CPU 时间,单核 CPU 自旋就是浪费,多核 CPU 自旋才能发挥优势。
在 Java 6 之后自旋锁是自适应的,比如对象刚刚的一次自旋操作成功过,那么认为这次自旋成功的可能性会高,就多自旋几次;反之,就少自旋甚至不自旋,总之,比较智能。
Java 7 之后不能控制是否开启自旋功能
3.4 偏向锁
轻量级锁在没有竞争时(仅自己的线程使用),每次重入的时候仍需执行CAS操作。
JAVA6 中引入了偏向锁来做进一步优化:只有第一次使用CAS将线程ID设置到对象的Mark Word头,之后发现这个线程ID时自己的就表示没有竞争,不用重新CAS。以后只要不发生竞争,这个对象就归该线程所有。
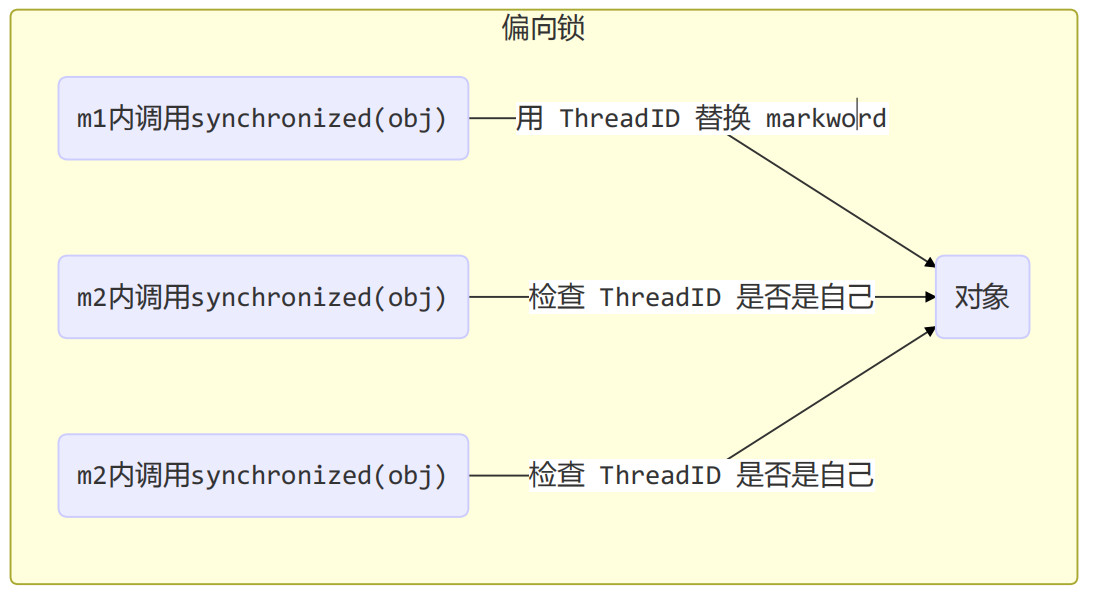
3.4.1 偏向状态
一个对象创建时:
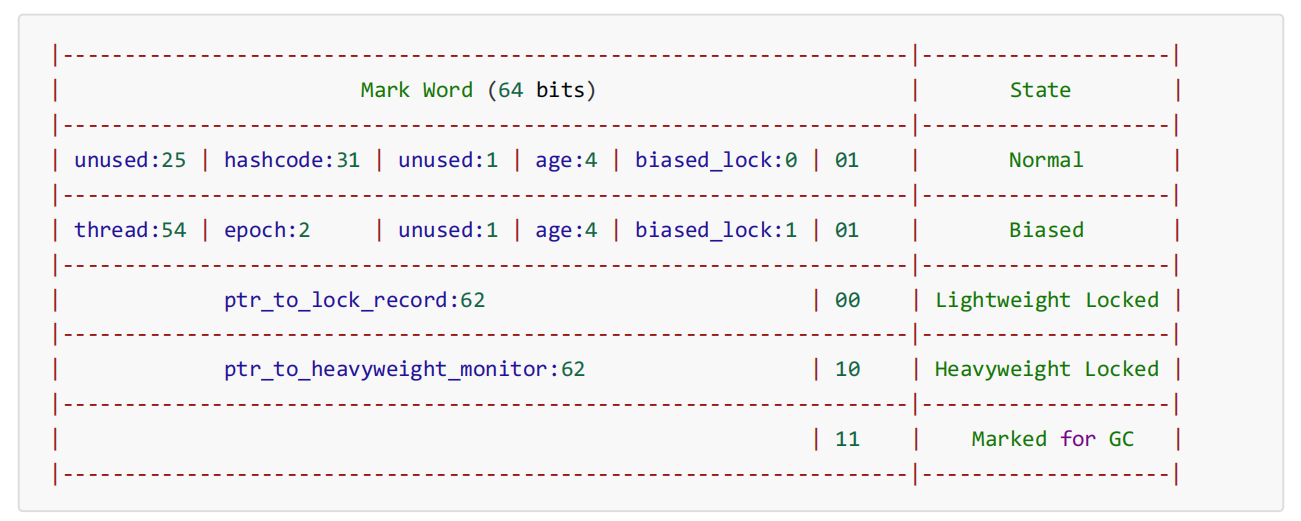
如果开启了偏向锁(默认开启),那么对象创建后,markword 值为 0x05 即最后 3 位为 101,这时它的thread、epoch、age 都为 0
偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加 VM 参数
-XX:BiasedLockingStartupDelay=0来禁用延迟如果没有开启偏向锁,那么对象创建后,markword 值为 0x01 即最后 3 位为 001,这时它的 hashcode、age 都为 0,第一次用到 hashcode 时才会赋值
3.4.2 撤销偏向锁的情况
- 调用hashCode方法后会禁用偏向锁,因为偏向锁的Mark Word中没有地方存hashcode了。如果本来时偏向锁,使用hashCode方法后,会自动退回Normal状态,然后把hashcode填入Mark Word。
- 其他线程使用偏向锁对象时,会将偏向锁升级为轻量级锁。(释放锁后,会回到normal状态,markword后三位为001)
- 调用wait/notify(只有重量级锁有这个功能)
3.4.3 批量重偏向
如果对象虽然被多个线程访问,但没有竞争,这时偏向了线程T1的对象仍有机会重新偏向T2,重偏向会重置对象的Thread ID。
当撤销偏向锁总次数达到 20 次后,jvm会觉得是不是偏向错了,于是会下一次在给这些对象加锁时 重新偏向至加锁线程。
底层原理:第20次会修改类的prototype header中的epoch,然后和对象的进行比较,发现不匹配,于是进行重偏向,然后修改对象的markword中的epoch。
3.4.4 批量撤销
当撤销偏向锁阈值达到 40 次后,jvm 会觉得,自己确实偏向错了,根本就不该偏向。于是整个类的所有对象都会变为不可偏向的,新建的对象也是不可偏向的。
注:20和40都是指本次就直接转换锁的类型了,而不是说等到下一次才转换
3.4.5 锁消除
JAVA会使用JIT即时编译器,当检测到对象是方法内的局部变量时(也就是说这个对象不可能被共享),于是会优化掉synchronized代码,最后实际时没有加锁的。
四、ReentrantLock 重入锁
相对于synchronized,它具备一下特点:
- 可中断
- 可以设置超时时间
- 可以设置为公平锁
- 支持多个条件变量
与synchronized一样,都支持可重入
1 | // 创建锁对象 |
4.1 特性
4.1.1 可重入
在一个方法运行完成后释放锁,别的方法可以重新获取锁。
4.1.2 可打断
在等待锁的过程中,可以被其他线程打断(终止等待)。
注意:lock.lock()是不可以被打断的。lock.lockInterruptibly()是可以被打断的。
别的线程使用 线程名.interrupt()即可打断该线程。
4.1.3 锁超时
lock.tryLock()立刻尝试获得锁,获得到返回True,反之False
lock.tryLock(时间,单位)在这段时间内一直尝试获得锁


4.1.4 公平性
ReentrantLock 默认是不公平的(不按照进入阻塞队列的顺序定谁先获得锁)
可以在创建对象的时候传入false(不公平)/true(公平)参数来设置是否公平。
公平锁一般没有必要,会降低并发度。
4.1.5 条件变量
synchronized 中也有条件变量,就是我们讲原理时那个 waitSet 休息室,当条件不满足时进入 waitSet 等待
ReentrantLock 的条件变量比 synchronized 强大之处在于,它是支持多个条件变量的,这就好比
synchronized 是那些不满足条件的线程都在一间休息室等消息
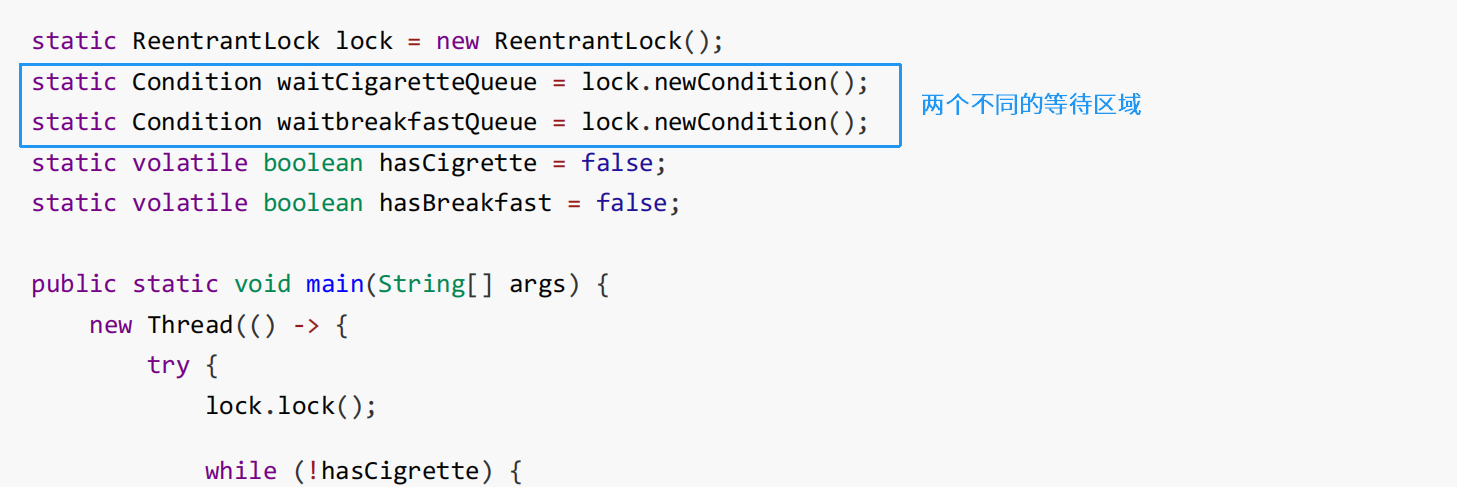
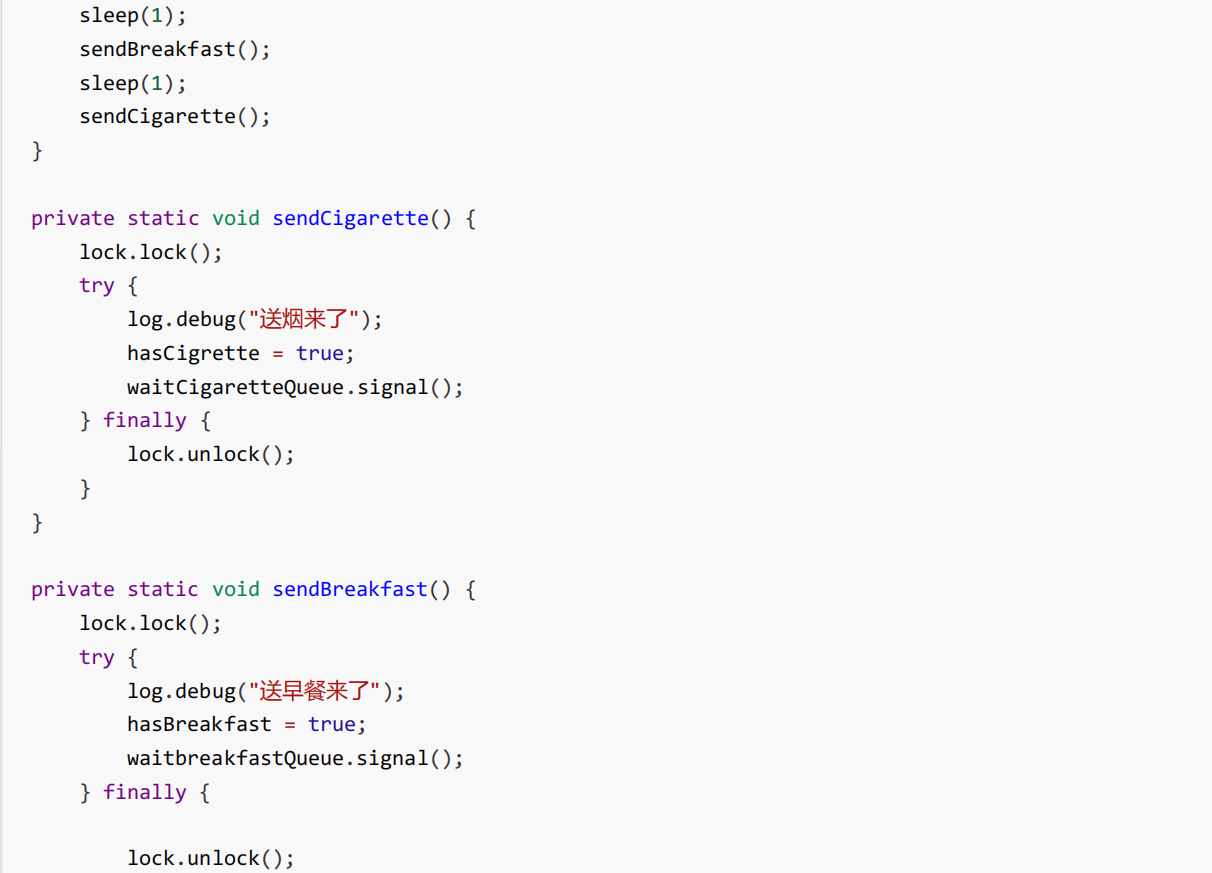
而 ReentrantLock 支持多间休息室,有专门等烟的休息室、专门等早餐的休息室、唤醒时也是按休息室来唤醒
使用要点:
await 前需要获得锁
await 执行后,会释放锁,进入 conditionObject 等待
await 的线程被唤醒(或打断、或超时)去重新竞争 lock 锁
竞争 lock 锁成功后,从 await 后继续执行
怎么让线程进入等待区域?
等待区域.await();
怎么让唤醒线程?
等待区域.signal();
举例:

五、volatile原理
volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
对 volatile 变量的写指令后会加入写屏障
对 volatile 变量的读指令前会加入读屏障
5.1 如何保证可见性
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
1 | public void actor2(I_Result r) { |
读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据
1 | public void actor1(I_Result r) { |
5.2 如何保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
不能解决指令交错:
- 写屏障仅仅保证之后的读操作能够读到最新的结果,但不能保证别的线程的读操作跑到他前面去
- 而有序性的保证也只是保证了本线程内相关代码不被重排序
(无法保证原子性)
5.3 double-checked locking 问题
以单例模式为例

外层的if语句在同步代码块之外使用了INSTANCE变量,在多线程环境下,有代码重排的问题。
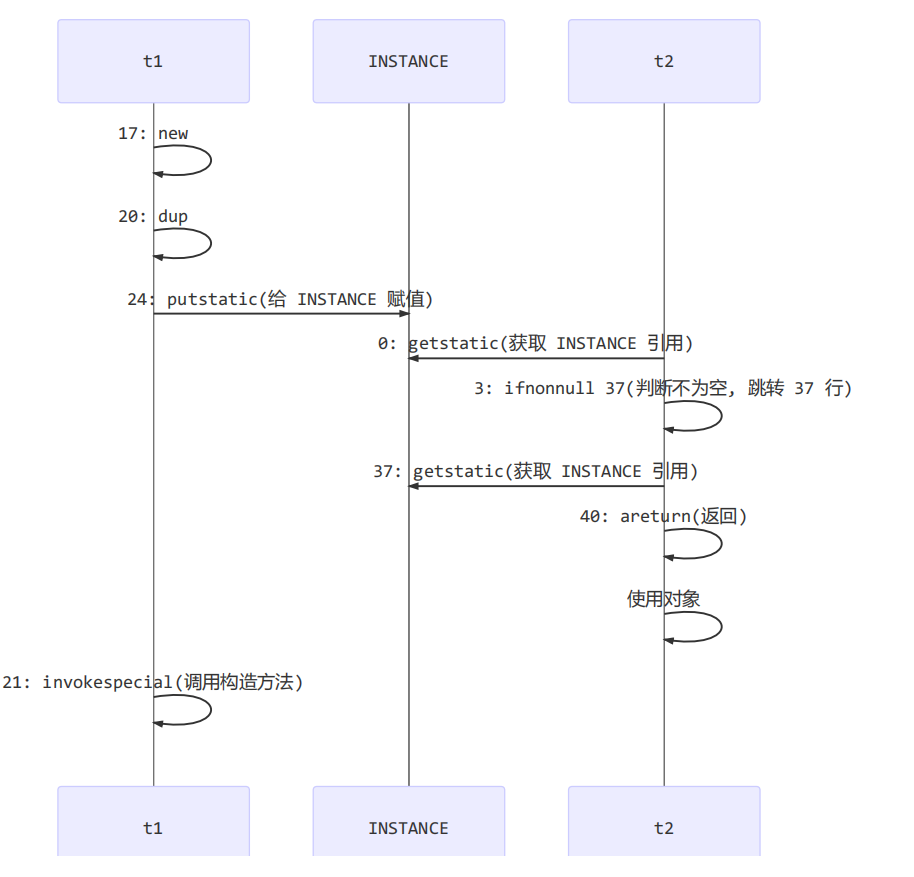
底层解释
t1线程的指令重排序后,先执行24行指令,将对象的地址赋值给INSTANCE,这时候t2线程进入外层的if语句,发现不是NULL,直接返回INSTANCE,就拿着这个地址(里面还没有内容)开始使用了。
synchronized只能保证只在共享代码块中的变量的可见性、有序性,不能留一点相关语句在外面。
解决方案
private static Singleton INSTANCE = null;
⬇️
private static volatile Singleton INSTANCE = null;
1 | // -------------------------------------> 加入对 INSTANCE 变量的读屏障 |
21:执行构造方法
24:把引用赋值给INSTANCE
写屏障保证了执行构造方法之后,才把引用赋值给INSTANCE
六、线程池
6.1 自定义线程池
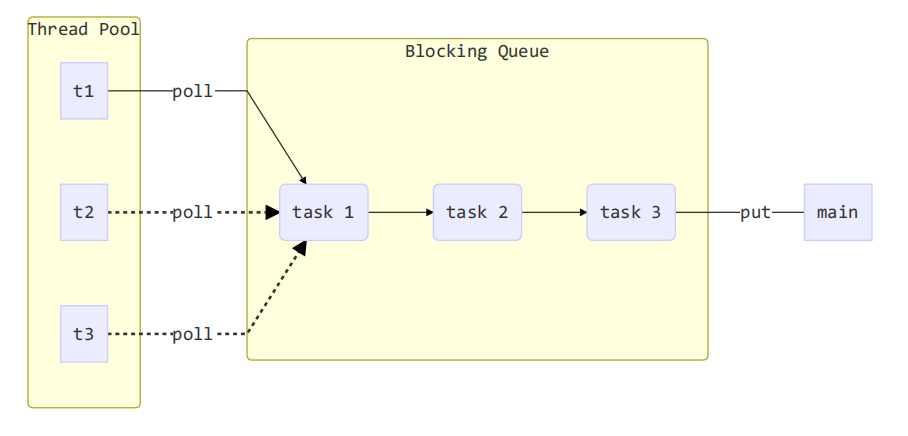
步骤1:自定义拒绝策略接口(函数式接口)
规定等待的任务数量超过等待队列了应该怎么办。

步骤2:自定义任务队列






步骤3:自定义线程池



步骤4:测试


6.2 ThreadPoolExecutor
6.2.1 线程池状态
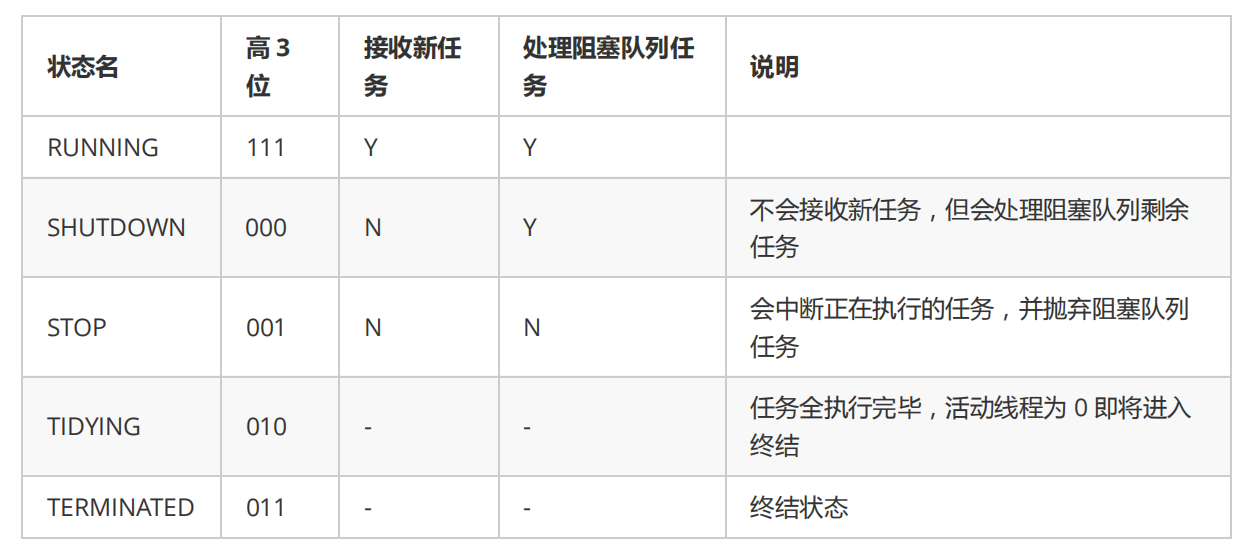
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量
6.2.2 构造方法
1 | public ThreadPoolExecutor(int corePoolSize, |
- corePoolSize 核心线程数目 (最多保留的线程数)
- maximumPoolSize 最大线程数目
- keepAliveTime 生存时间 - 针对救急线程(控制没活做了还要生存多久)
- unit 时间单位 - 针对救急线程
- workQueue 阻塞队列
- threadFactory 线程工厂 - 可以为线程创建时起个好名字
- handler 拒绝策略
最大线程数 = 核心线程 + 救急线程
流程:
线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue 队列排队,直到有空闲的线程。
如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize - corePoolSize 数目的线程来救急。
只有等救急线程也被用完了,再来线程才会执行拒绝策略。
- AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
- CallerRunsPolicy 让调用者运行任务
- DiscardPolicy 放弃本次任务
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之

6.2.3 工厂方法 —— newFixedThreadPool
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
特点:
- 核心线程数 = 最大线程数(没有救急线程),因此也无需设置超时时间
- 阻塞队列是无界的,可以放任意数量的任务
适用于任务量已知,相对耗时的任务。
ThreadFactory方法——可以自定义线程的名字,是否为守护线程…
6.2.4 工厂方法 —— newCachedThreadPool
补充:工厂方法——帮你创建对象的方法(不同的工厂方法,可以提供不同的实现)
1 | public static ExecutorService newCachedThreadPool() { |
特点:
- 核心线程数是 0, 最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60s,意味着
- 全部都是救急线程(60s 后可以回收)
- 救急线程可以无限创建
- 队列采用了 SynchronousQueue 实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货)

整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲1min后释放线程。
适合任务数比较密集,但每个任务执行时间较短的情况。
6.2.5 工厂方法 —— newSingleThreadExecutor
1 | public static ExecutorService newSingleThreadExecutor() { |
希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
区别:
- 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作
- Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改
- FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法
- Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改
- 对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
6.2.6 提交任务
1 | // 执行任务 |
6.2.7 关闭线程池
shutdown
1 | /* |
1 | public void shutdown() { |
shutdownNow
1 | /* |
1 | public List<Runnable> shutdownNow() { |
其他方法
1 | // 不在 RUNNING 状态的线程池,此方法就返回 true |
七、线程安全的集合类
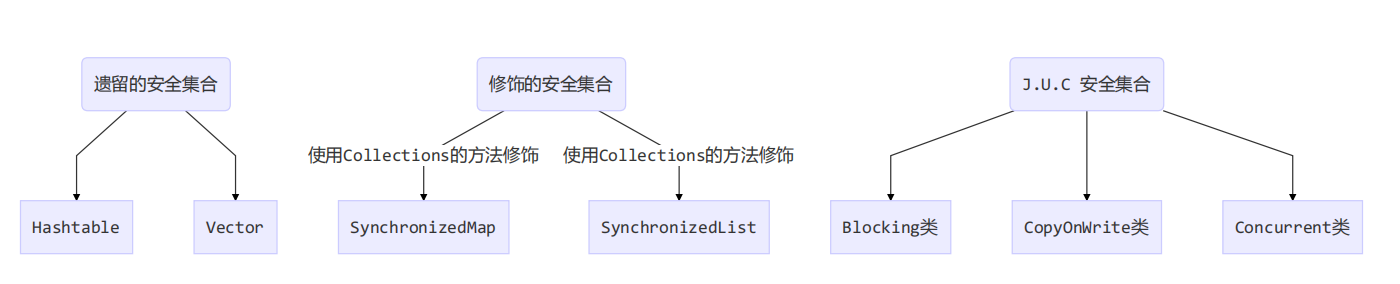
Blocking 大部分实现基于锁,并提供用来阻塞的方法
CopyOnWrite 之类容器修改开销相对较重
Concurrent 类型的容器
内部很多操作使用 cas 优化,一般可以提供较高吞吐量
弱一致性
遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历,这时内容是旧的
求大小弱一致性,size 操作未必是 100% 准确
读取弱一致性
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出ConcurrentModificationException,不再继续遍历
7.1 ConcurrentHashMap
当数组长度超过64且链表长度大于8时,会将链表转化为红黑树
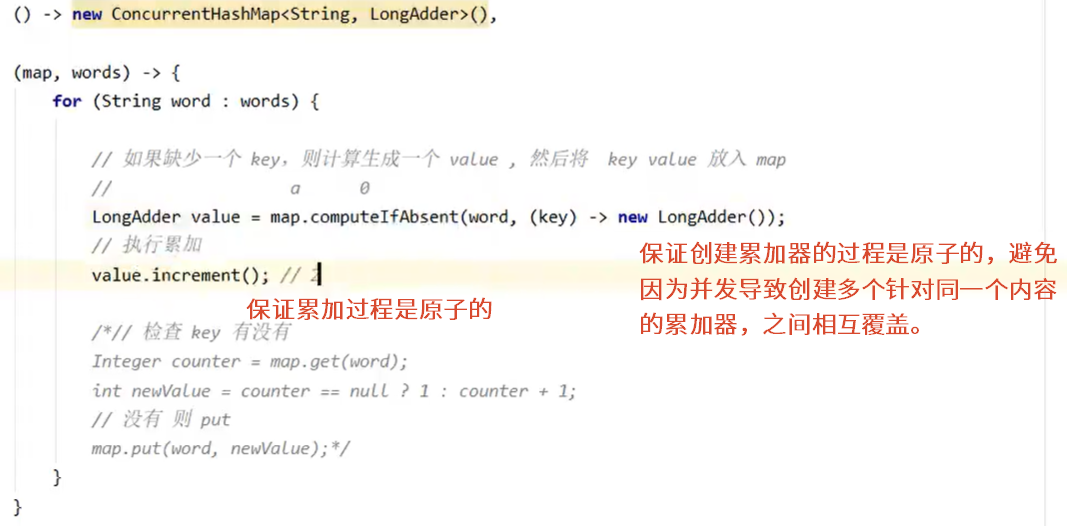
7.1.1 应用场景举例——统计字母出现次数
7.1.2 JDK7 HashMap并发死链
- HashMap底层:数组+链表
- 元素个数超过数组长度的75%时,会触发扩容
- 当两个线程都触发扩容的时候,会导致死链。(其中一个线程已经将链表结构改变了,但是另外一个线程在这之前就拿到了链表的引用,再次进行修改,导致链表产生回环,卡死。)【例如:1->2->1】
7.1.3 JDK8 ConcurrentHashMap
构造器分析
实现了懒惰初始化,在构造方法中仅仅计算了table的大小,以后在第一次使用时才会真正创建

get流程

put流程
以下数组简称table,链表简称bin